

Understanding Synthetic Data: Is It the Future of Artificial Intelligence?
In the digital age, there is no dearth of data. As per some estimates, roughly 2.5 quintillion bytes of data is produced every day. That’s 2.5 followed by 18 zeroes.
Moreover, it’s well-understood that high-quality artificial intelligence (AI) and machine learning (ML) models need access to large amounts of high-quality data to work well.
Therefore, with so much data generated on a regular basis, there should be no problem using it to improve AI and ML models. Isn’t that so?
Unfortunately, no.
That’s the thing – Having a large amount of data doesn’t mean everyone can actually use it. Companies and institutions protect their users’ privacy and restrict access to datasets (and rightly so).
It means that often there’s not enough data for AI developers and researchers to work on.
That’s where synthetic data comes in. It’s a quickly expanding trend in the field of data science. MIT Technology review even lists synthetic data as among the top 10 breakthrough technologies of 2022.
So, here in this article, we’ll try to understand what synthetic data is. We’ll also look at its use cases and future implications.
What is synthetic data?
In the simplest terms, synthetic data is a computer-generated alternative to real-world data.
The term “synthetic” refers to data that’s being generated by computer algorithms (i.e. in a digital world) instead of being collected in the real world. It’s basically annotated information generated by computer algorithms.
Synthetic data incorporates an original dataset’s properties and distribution and can thus reflect real-world data. The end result is a new dataset that’s statistically similar to the original data but different enough to not give away any personal information.
While it may be artificial, research suggests that synthetic data can be as good as real data (sometimes even better) when it comes to training AI models.
Gartner even suggested that –
“By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.“
Why is synthetic data important?
Frameworks like TensorFlow and PyTorch have become much easier to use. Even the predesigned models for natural language processing and computer vision have become more powerful.
Therefore, currently, the biggest problem for data scientists is the collection and handling of data. That’s because –
- Collecting and using sensitive data can cause privacy concerns and leave businesses vulnerable to data breaches
- Data can be costly to collect
So, data scientists often struggle with training an accurate model within a given timeframe.
This is where synthetic helps. The primary purpose of synthetic data is to be robust and versatile enough that it can be used for training ML models.
Synthetic data does a great job of joining utility and privacy goals, with a very low risk of reidentification.
Synthetic data can also be generated to meet specific needs, unlike real-life data. This can be useful when –
- There are privacy requirements to limit data availability
- Data is needed for product testing
- There is a need for training data for ML algorithms
Benefits offered by synthetic data
Some key benefits offered by synthetic data include –
- Protect data privacy by improving de-identification and creating sandboxes to easily share data within or outside the organization
- Reduce the cost of AI projects in terms of data collection and labeling
- Mitigate data scarcity
- Improve the generalization of ML models by solving imbalance problems
- Boost AI fairness to fix possible bias and ensure a more inclusive AI application
- Lay the foundation for safe and better software testing
Types of synthetic data
There are several types of synthetic data, each serving a different purpose. Some key types are –
- Synthetic text – This is artificially-generated text. Think of language models like the super popular GPT-3 that does a great job of generating human-like text.
- Synthetic media – These are artificially rendered videos or images that have properties close-enough to real-world data. Take the example of this website – ‘thispersondoesnotexist.com’. It shows you photos of individuals generated who do not exist in real life. It uses generative AI to create these images.
For reference, you can check out the image below –

- Synthetic tabular data – It refers to artificial tabular data that can mimic real-life data stored in tables. It can be anything like a patient database or a financial log.
5 top use cases of synthetic data
Synthetic data can be used in just about any machine learning task. However, the most common use cases of synthetic data are in the following industries –
- Financial services – In finance, synthetic data is extremely helpful in fraud detection. Using synthetic fraud data, new fraud prevention and detection methods can be tested for effectiveness. The industry also uses synthetic data for customer analytics to analyze customer behavior.
- Manufacturing – In the manufacturing industry, synthetic data is used for quality assurance by enabling more effective testing of QC systems and improving their performance.
- Healthcare – Synthetic data helps healthcare professionals maintain the confidentiality of patient data despite sharing it externally or internally. It is also used in clinical trials as a baseline for future studies when there is a lack of real data.
- Robotics and autonomous vehicles – Autonomous things (AuT) like self-driving cars and autonomous robots pioneered the use of synthetic data. Since real-life testing of robotic systems is slow and expensive, synthetic data helps speed up the process. It allows companies to test their solutions using thousands of simulations.
- Security – Organizations use synthetic data to boost both offline and online security. This is done either by using synthetic training data for improving video surveillance or protecting against deep fakes online.
Challenges associated with synthetic data
Synthetic data isn’t a perfect solution for all our data woes. Despite the advantages it brings, there are many challenges associated with it. Some of the key challenges include –
- Synthetic data may not have some of the outliers that real data has. These outliers may at times be necessary to train reliable ML models.
- The quality of synthetic data can be highly variable.
- Since synthetic data is dependent on the quality of the input data. So, if the input data is biased, the generated synthetic data can have bias too.
- Synthetic data is still an emerging concept so user acceptance is more challenging.
What does the future of synthetic data look like?
Gartner suggests that synthetic data will completely take over real data in AI, ML models by 2030. The graph below clearly explains the growing importance of synthetic data.
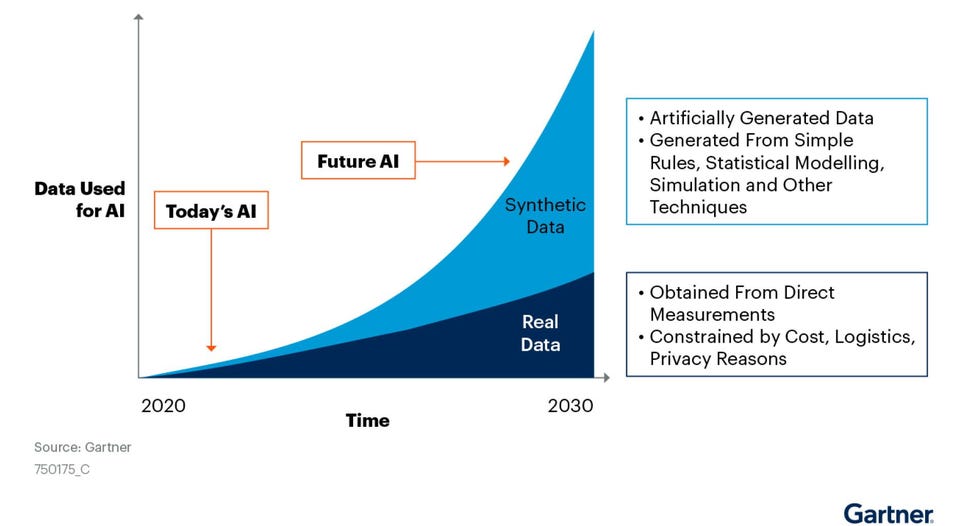
By making data vastly more accessible and affordable, synthetic data will undermine real-world data and offer strong competition. It will democratize access to data at scale and level the playing field.
Synthetic data will also massively boost the development of autonomous vehicles and empower a whole new generation of AI-first products. It is definitely the future of AI.
Enjoyed reading the article? You can also check out these –
